OK今天的文章,會是昨天的延續,因為我怕一次教太多,我怕大家吸收不了,昨天教到Clean data,今天繼續下去
粗體為今天會講到的步驟
1.匯入資料
2.選擇要使用的 Columns
3.清理資料
4.資料前處理(資料型態轉換)
5.切分資料為訓練及測試資料集
6.匯入模型
7.訓練模型
8.評分模型
9.評估模型(和評分模型的不同之處在於,評估模型會計算出該模型的MAE / RMSE 等值,提供更直觀的模型評估方式)
(來源:Ashe Liao)
下一步是資料轉換,傳統上做分類問題時使用的隨機森林有個缺點,資料型態必須是 numeric 的值才有辦法餵入模型,因此在 Notebook 上常常要做一系列的資料型態轉換,但是!!!!!在Azure Machine Learning Studio 上有一個特別的功能Edit meta data(複製在左欄位搜尋),這個模組可以自動把選定的欄位轉換成 category 的資料,就不用再做複雜的資料型態轉換,可以直接以類別資料型態餵入模型,是相當方便又好用的功能。
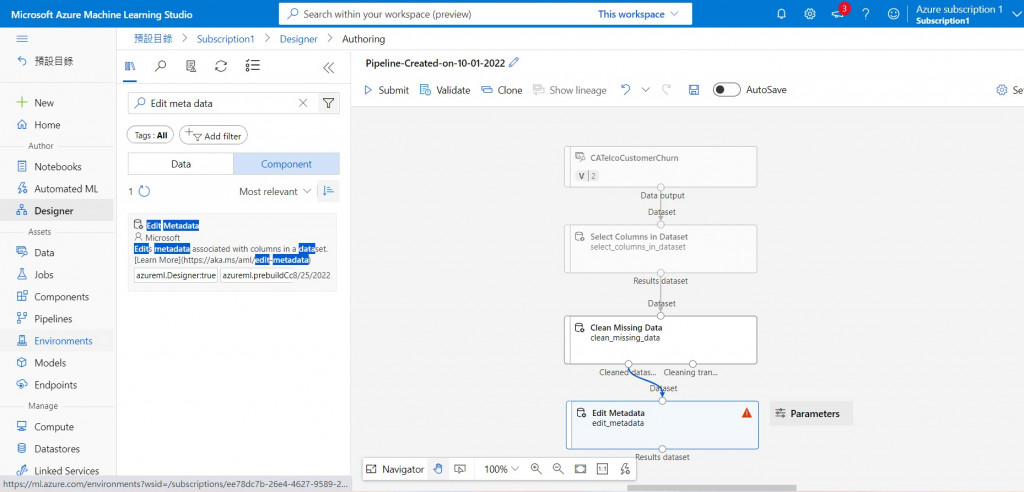
這次的紅色驚嘆號也使因為沒有輸入Cloun,照我的輸入即可。
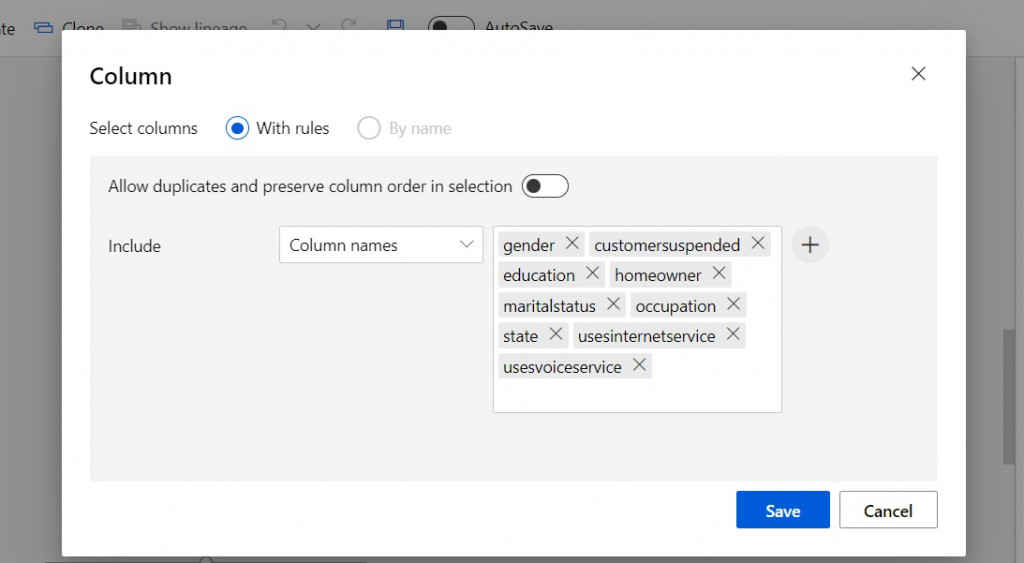
然後要接著設定資料轉換的型態,在 Categorical 選擇 Categorical 以及 Fields 選取 Features,跟下圖一致。
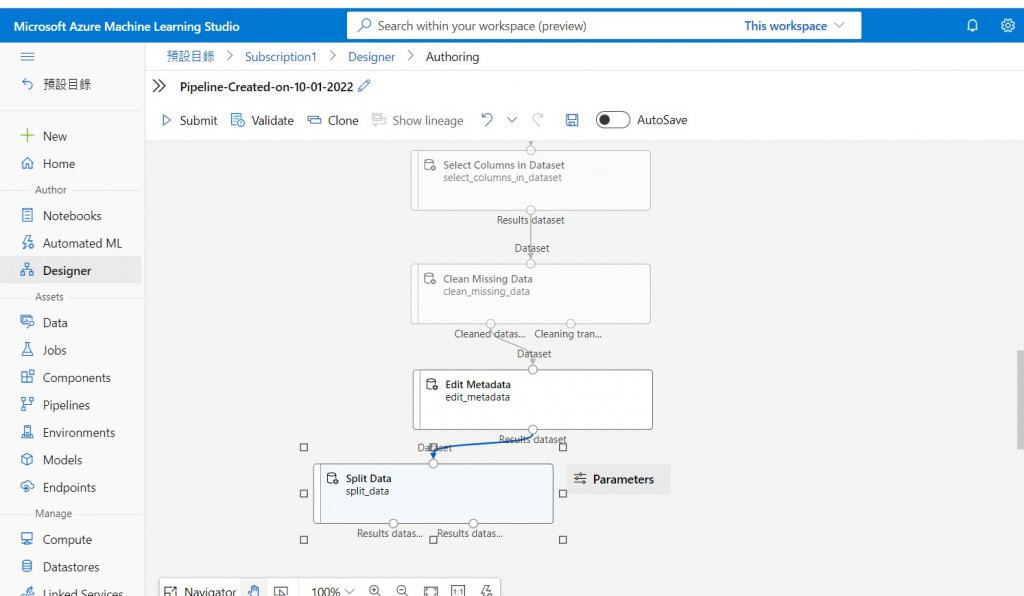
我們要將資料切分為訓練資料以及測試資料,首先先在左側搜尋欄中搜尋 Split data 並拖拉至工作區與上一塊連接起來。
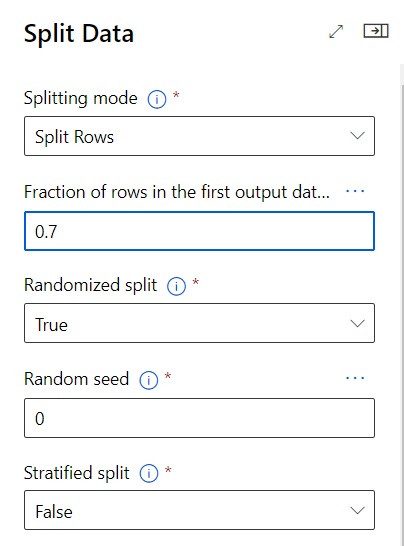
然後我們選擇70%的資料為訓練資料,剩下的30%為測試資料,並且按照亂數來切分。(若要確認每次的切分成果相同,可以設定 Random seed 參數為一個不為 0 的正整數。)
待續......


 iThome鐵人賽
iThome鐵人賽